JSON (JavaScript Object Notation) is a commonly used semi-structured data type. With the self-describing schema structure, JSON can hold all data types, including multi-level nested data types, such as Array, Object, etc. JSON takes advantage of high flexibility and easy dynamic expansion compared with the structured data types that must strictly follow the fields in a tabular data structure.
As data volume increases rapidly in recent years, many platforms have started to use and get the most out of semi-structured data types (such as JSON). For example, the JSON data shared by various platforms through open interfaces, and the public datasets and application logs stored in JSON format.
Databend supports structured data types, as well as JSON. This post dives deeply into the JSON data type in Databend.

Working with JSON in Databend
Databend stores semi-structured data as the VARIANT (also called JSON) data type:
CREATE TABLE test
(
id INT32,
v1 VARIANT,
v2 JSON
);
The JSON data needs to be generated by calling the parse_json or try_parse_json function. The input string must be in the standard JSON format, including Null, Boolean, Number, String, Array, and Object. In case of parsing failure due to invalid string, the parse_json function will return an error while the try_parse_json function will return a NULL value.
INSERT INTO test VALUES
(1, parse_json('{"a":{"b":1,"c":[1,2]}}'), parse_json('[["a","b"],{"k":"a"}]')),
(2, parse_json('{"a":{"b":2,"c":[3,4]}}'), parse_json('[["c","d"],{"k":"b"}]'));
SELECT * FROM test;
+----+-------------------------+-----------------------+
| id | v1 | v2 |
+----+-------------------------+-----------------------+
| 1 | {"a":{"b":1,"c":[1,2]}} | [["a","b"],{"k":"a"}] |
| 2 | {"a":{"b":2,"c":[3,4]}} | [["c","d"],{"k":"b"}] |
+----+-------------------------+-----------------------+
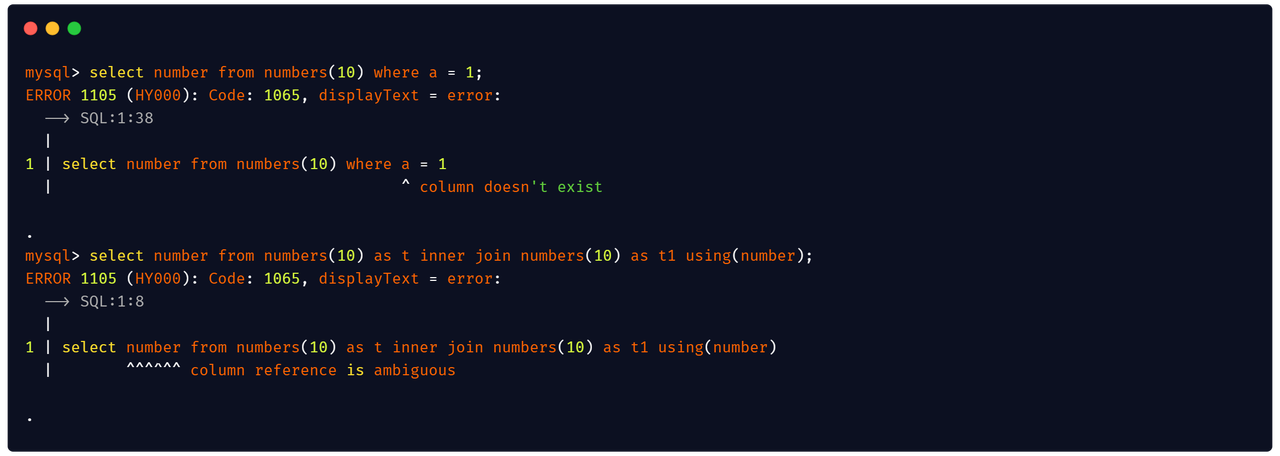
JSON usually holds data of Array or Object type. Due to the nested hierarchical structure, the internal elements can be accessed through JSON PATH. The syntax supports the following delimiters:
:: Colon can be used to obtain the elements in an object by the key..: Dot can be used to obtain the elements in an object by the key. Do NOT use a dot as the first delimiter in a statement, or Databend would consider the dot as the delimiter to separate the table name from the column name.[]: Brackets can be used to obtain the elements in an object by the key or the elements in an array by the index.
You can mix the three types of delimiters above.
SELECT v1:a.c, v1:a['b'], v1['a']:c, v2[0][1], v2[1].k FROM test;
+--------+-----------+-----------+----------+---------+
| v1:a.c | v1:a['b'] | v1['a']:c | v2[0][1] | v2[1].k |
+--------+-----------+-----------+----------+---------+
| [1,2] | 1 | [1,2] | "b" | "a" |
| [3,4] | 2 | [3,4] | "d" | "b" |
+--------+-----------+-----------+----------+---------+
The internal elements extracted through JSON PATH are also of JSON type, and they can be converted to basic types through the cast function or using the conversion operator ::.
SELECT cast(v1:a.c[0], int64), v1:a.b::int32, v2[0][1]::string FROM test;
+--------------------------+---------------+------------------+
| cast(v1:a.c[0] as int64) | v1:a.b::int32 | v2[0][1]::string |
+--------------------------+---------------+------------------+
| 1 | 1 | b |
| 3 | 2 | d |
+--------------------------+---------------+------------------+
Parsing JSON from GitHub
Many public datasets are stored in JSON format. We can import these data into Databend for parsing. The following introduction uses the GitHub events dataset as an example.
The GitHub events dataset (downloaded from GH Archive) uses the following JSON format:
{
"id":"23929425917",
"type":"PushEvent",
"actor":{
"id":109853386,
"login":"teeckyar-bot",
"display_login":"teeckyar-bot",
"gravatar_id":"",
"url":"https://api.github.com/users/teeckyar-bot",
"avatar_url":"https://avatars.githubusercontent.com/u/109853386?"
},
"repo":{
"id":531248561,
"name":"teeckyar/Times",
"url":"https://api.github.com/repos/teeckyar/Times"
},
"payload":{
"push_id":10982315959,
"size":1,
"distinct_size":1,
"ref":"refs/heads/main",
"head":"670e7ca4085e5faa75c8856ece0f362e56f55f09",
"before":"0a2871cb7e61ce47a6790adaf09facb6e1ef56ba",
"commits":[
{
"sha":"670e7ca4085e5faa75c8856ece0f362e56f55f09",
"author":{
"email":"support@teeckyar.ir",
"name":"teeckyar-bot"
},
"message":"1662804002 Timehash!",
"distinct":true,
"url":"https://api.github.com/repos/teeckyar/Times/commits/670e7ca4085e5faa75c8856ece0f362e56f55f09"
}
]
},
"public":true,
"created_at":"2022-09-10T10:00:00Z",
"org":{
"id":106163581,
"login":"teeckyar",
"gravatar_id":"",
"url":"https://api.github.com/orgs/teeckyar",
"avatar_url":"https://avatars.githubusercontent.com/u/106163581?"
}
}
From the data above, we can see that the actor, repo, payload, and org fields have a nested structure and can be stored as JSON. Others can be stored as basic data types. So we can create a table like this:
CREATE TABLE `github_data`
(
`id` VARCHAR,
`type` VARCHAR,
`actor` JSON,
`repo` JSON,
`payload` JSON,
`public` BOOLEAN,
`created_at` timestamp(0),
`org` json
);
Use the COPY INTO command to load the data:
COPY INTO github_data
FROM 'https://data.gharchive.org/2022-09-10-10.json.gz'
FILE_FORMAT = (
compression = auto
type = NDJSON
);
The following code returns the top 10 projects with the most commits:
SELECT repo:name,
count(id)
FROM github_data
WHERE type = 'PushEvent'
GROUP BY repo:name
ORDER BY count(id) DESC
LIMIT 10;
+----------------------------------------------------------+-----------+
| repo:name | count(id) |
+----------------------------------------------------------+-----------+
| "Lombiq/Orchard" | 1384 |
| "maique/microdotblog" | 970 |
| "Vladikasik/statistic" | 738 |
| "brokjad/got_config" | 592 |
| "yanonono/booth-update" | 537 |
| "networkoperator/demo-cluster-manifests" | 433 |
| "kn469/web-clipper-bed" | 312 |
| "ufapg/jojo" | 306 |
| "bj5nj7oh/bj5nj7oh" | 291 |
| "appseed-projects2/500f32d3-8019-43ee-8f2a-a273163233fb" | 247 |
+----------------------------------------------------------+-----------+
The following code returns the top 10 users with the most forks:
SELECT actor:login,
count(id)
FROM github_data
WHERE type='ForkEvent'
GROUP BY actor:login
ORDER BY count(id) DESC
LIMIT 10;
+-----------------------------------+-----------+
| actor:login | count(id) |
+-----------------------------------+-----------+
| "actions-marketplace-validations" | 191 |
| "alveraboquet" | 59 |
| "ajunlonglive" | 50 |
| "Shutch420" | 13 |
| "JusticeNX" | 13 |
| "RyK-eR" | 12 |
| "DroneMad" | 10 |
| "UnqulifiedEngineer" | 9 |
| "PeterZs" | 8 |
| "lgq2015" | 8 |
+-----------------------------------+-----------+
Performance Optimization
The JSON data generally is saved in plaintext format and needs to be parsed to generate the enumeration value of serde_json::Value every time the data is read. Compared to other basic data types, handling JSON data takes more parsing time and needs more memory space.
Databend has improved the read performance of JSON data using the following methods:
To speed up the parsing and reduce memory usage, Databend stores the JSON data as JSONB in binary format and uses the built-in j_entry structure to hold data type and offset position of each element.
Adding virtual columns to speed up the queries. Databend extracts the frequently queried fields and the fields of the same data type and stores them as separate virtual columns. Data will be directly read from the virtual columns when querying, which makes Databend achieve the same performance as querying other basic data types.